Kürzlich hatte ich eine gute Diskussion zum Einsatz von LLMs in der Software-Entwicklung, die eine gewisse Differenzierung erlaubte. Derzeit werden Diskussionen rund um den Einsatz sehr schwarz-weiß geführt – ich komme von der AI-kritischen Seite und Argumente rund um Ressourcen-Verbrauch, Finanz-Bubble, Ausbeutung, Sicherheit, Psychosen, Slop sind hiermit acknowledged, werden in der folgenden Betrachtung, aber nicht noch einmal aufgegriffen.
Im Einsatz von LLMs unterscheide ich zwischen zwei Arten: Ist das LLM eine Funktion innerhalb eines größeren Prozesses oder steuert das LLM diesen Prozess. Macht du Bildbearbeitung und nutzt in deiner Software ein Feature zum sauberen Markieren eines Object, ist es Ersteres. Du könntest es ohne AI machen, ist aber mehr administrativer Aufwand, der kreative Prozess liegt bei mir. Du hast eine Automatisierung, die deterministische Schritte geht und ein Schritt ist ein Prompt zu einem LLM, ist ebenfalls Ersteres, solange das LLM eine einzelne klare Funktion, zB eine Qualifizierung erfüllt. Zweiterem entspricht der Ansatz “mach mir alles”, wenn der kreative Prozess an sich an das LLM abgegeben wird. The Oatmeal hat das schön zusammengefasst.
Ähnlich sehe ich es auch bei Software-Entwicklung. Du kannst einen sehr gezielten LLM Einsatz haben, der an den richtigen Stellen sehr hilfreich ist und eine gute Ergänzung ist. Für mich ist dass, wenn ich komplexen Code debuggen (stell dir 5x verschachtelte SQL vor und frag nicht woher die kommen) und das LLM erstaunlich oft ihr beschriebene Fehler auflösen kann. Meine Erfolge mit Coding Agents sind dagegen gering, was hauptsächlich daran liegt, dass ich sie mit lokalen Open-Source LLMs und zu schwacher Hardware betrieben habe.
Ich war letztes Jahr zu einem n8n-Meetup. N8n nutze ich öfters, wenn es darum geht schnell Automatisierungen zu prototypen. Umgeben war ich von Marketing-Personen und Product-Manager*Innen, die stolz ihre selbst gebauten Systeme zeigten. Automatisierungen wild zusammen geklickt aus 5 Services ohne Rücksicht auf Performance, Datenschutz, Skalierbarkeit und Stabilität. Aber sie waren stolz drauf und es erfüllte für sie eine Aufgabe, die vorher nicht erfüllt werden konnte. Was in der Luft schwang, war eine Abwertung der eigenen IT-Abteilung. Du hörtest den Frust von Menschen, die zu oft “nein, machen wir nicht”, “nein, keine Ressourcen” oder “wir setzen es aufs Backlog, du hast es in 4 Monaten” zu hören bekommen haben. Ihnen ist egal, dass ihre AI-Lösungen alle paar Wochen zusammenbrechen und ein Datenschutz-Albtraum sind.
Im Product Management gibt es eine Organisationsmethode von Flughöhen (Flight levels). Du kannst Initiativen in verschiedenen Flughöhen haben, die alle hohe Prioritäten genießen, aber unterschiedliche Zeithorizonte haben. Die Quickwins auf niedriger Flughöhe sind schnell eingeführt, lassen sich schnell ändern und können schnell wieder ersetzt werden. In der mittleren Flughöhe sind Themen mit Blick auf das nächste Projekt, die über die nächsten Wochen/Monate relevant werden. Die strategischen Themen sind oberste Flughöhe und die dicken Bretter. Diese ändern sich selten und haben einen langen Zeithorizont.
Software kann ebenfalls in diese Flughöhen eingeteilt werden und je nach Höhe kommen unterschiedliche Anforderungen. Dein Einmal-Script von der AI geschrieben, dass du nicht wieder verwenden willst ist ein Quickwin vorausgesetzt es ist bei unkritischen Dingen im Einsatz. Die vibe-gecodete Anwendung ist eine nächste Flughöhe mit überschaubarer Lebensdauer aber praktischem Nutzen. Es wird oft kaputtgehen, aber das macht nichts. Es hilft dir, niemand anderen und du kannst die Verantwortung für dich tragen. Die nächste Höhe ist Software, die mit Zugriff auf das Lethal Trifectar – Private Daten (Kreditkarte), Zugriff ins Internet(kann Daten zu Webseiten schicken) und Zugriff durch Unbefugte (LLM führt Inhalt einer E-Mail aus) – hat. Hier erreichen wir den Punkt an dem Vibe-Coding nicht mehr empfehlenswert ist und wo LLM-Einsatz nur noch in isolierten einzelnen Funktionen sinnvoll sein könnte. In der höchsten Flughöhe ist die Software das Zentrum deines Businessmodells. Soll sie für Jahre stabil und skalierbar sein, so halte LLMs davon fern. Hier spielen Architektur, Software-Design, Performance und langfristiges Komplexitäts-Management eine große Rolle und können hier nicht LLMs nicht mithalten.
Nach diesen Flightleveln bewerte ich für mich, wann welcher AI-Einsatz tolerabel ist. Kenne deine Werkzeuge, deine Risiken und wann du einen Bogen drum herum machst.
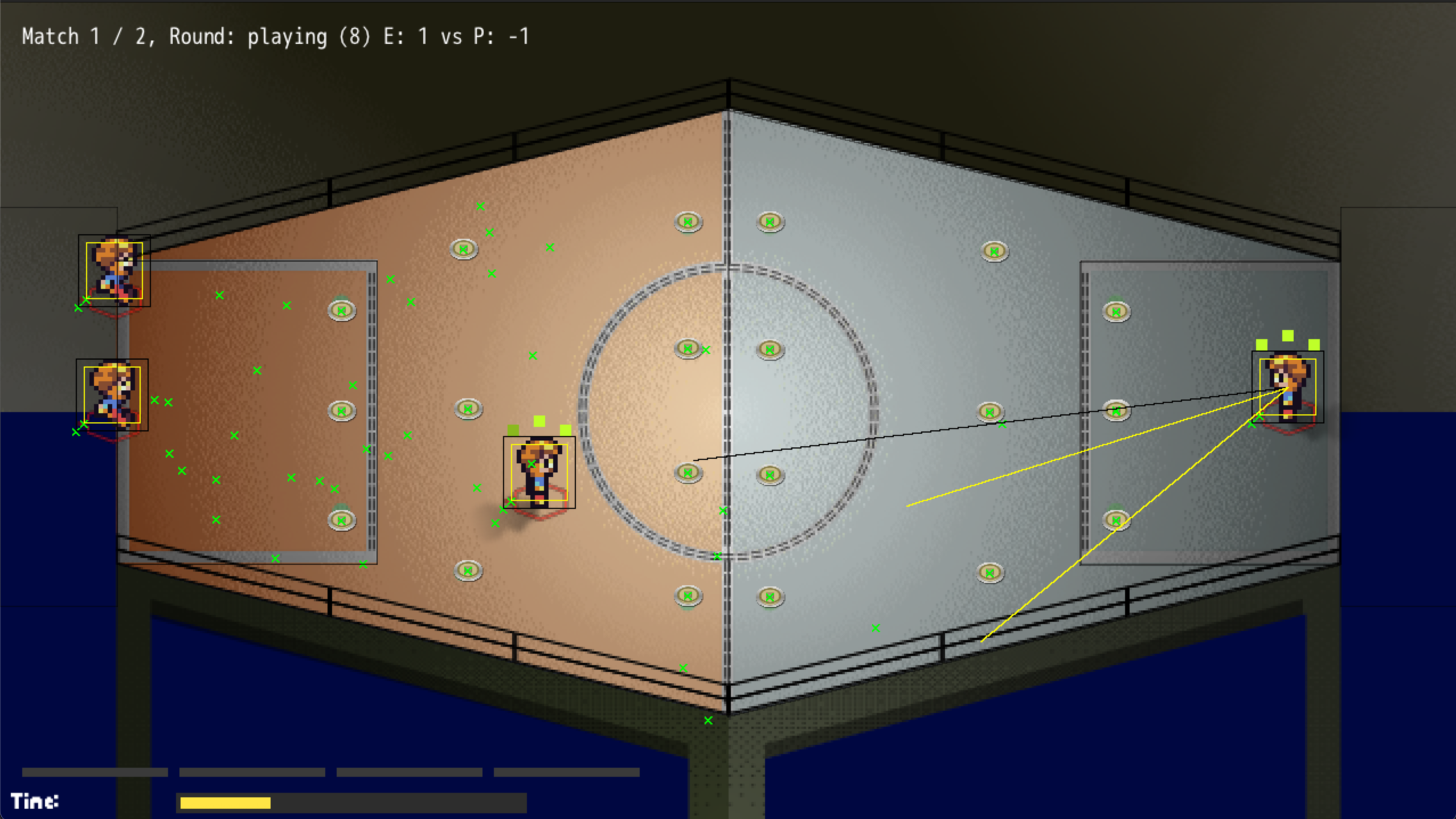
The game ended up being quite similar to hat I had in mind. It is inspired by The Legend Of Korra by having an arena with multiple zones and two teams who have to push the opponent team back in their zones and gain territory. Pushing them off the edge leads to a Knockout and instant win. So the players goal is to balance their strategy between offensively trying to push the enemy back, and defensely avoiding to get hit and thus increasing risk of being pushed back yourself. The whole gamplay is implemented on this balance – with a lot of room fore refinement.
Two teams face-off in an elevated arena. Players of both teams have an elemental skill – fire, water, earth. Their goal is to push their opponents back on their field, thereby gaining territory. Match winner is who wins 3 rounds by gaining the most territory in each. You have to attack to proceed, while defend against the attacks of your opponents. All players on the field have 3 critical properties: Accuracy, Balance and Power. Accuracy determines how precise attacks are, while power determines how far your range attack goes. Balance is a defensive property describing how “steady” you are when receiving attacks – loose your balance, you get pushed back more easy. Each elemental attack addresses one poverty. Fire attacks reduce power. Water attacks reduce accuracy. Earth attacks reduce Balance. This creates a game dynamic where you have to quickly strategize, see and take opportunities and switch between offense and defense.
The steering is based on WADS movement with auto-aiming to a selected enemy. I was and I am still trying different input sets. I was considering something League-Of-Legends or Heroes Of The Storm, but the characters require a different mobility. The target is still inspired by it. I am still trying how to add game controller support. Two actions I have yet to implement and try how they affect game play is blocking (defensive position to absorb projectile with minimal damage) and dashing (fast avoiding movement).
Speaking of LoL. Right now for each elemental bender only one simple attack is implemented. This is where I have plenty of ideas also inspired by LoL and HotS, I may try in the future. I would like to make the elements more different. Right now the only difference is in health effects. Water reduces accuracy which increases the margin of error when firing projectiles. This reduces their offensive capability. Earth has the biggest wooms and reduces balances, being hid by earth makes the opponent slide more, thus increasing risk of being pushed over the line. Lastly hitting with fire reduces the Power of the hit character. Power being the ability to throw an attack and the strength of the attack. What I switched around a few times is weather this is rather a bullet hell (dozents of projectiles, each hit doing minimal damage) or more strategic (few projectiles, strong damage). Between those extremes, I’m more on the bullet hell end at the moment. With blocking and dashing, and different steering, I could imaging leaning more into the strategic aspects again.
The AI is already doing it’s thing, but here is also a lot of room for improvement, for better play, strategy, coordination and personalities. Lastly, right now you only have the quickmatch. I could imagine having a campaign where you team has to work through the full tournament in multiple rounds to win, with a small embedded story. This is where we are in let’s-dream territory. I may add some new things over time, but for now I’m happy with the state I have now. For a 3 months project in my free time I’m proud of the result. I hope you enjoy it as much as me. 🙂
Vor zwei Jahren bestätigte sich eine langjährige Ahnung – ich habe ADHS. Seitdem konnte ich viele Erfahrungen und Seiten an mir entdecken, die Menschen mit ADHS teilen. Drei Posts sind dabei so hängen geblieben, dass sie für mich fast als Lakmus-Test für ADHS dienen, da sie einige fundamentale Aspekte aufgreifen, wie sich für mich Leben mit ADHS anfühlt und welche Spuren dies hinterlässt. Fast ein Lakmus-Test weil, der reale Lakmustest ist Medikamente zu probieren, da – im Gegensatz zu Autismus – ADHS mit Medikamenten unterstützt werden kann – Story for another day.
I spent Christmas and New Years Eve somewhere in the German country side in my sister’s house. I brought music equipment, writing and painting utensils ready to lock myself in and only get out, once some art was created. Then I got sick for 5 days and almost missed Christmas. As I recovered, I woke up one night with a game idea and started scribbling notes, which turned into this prototype.
I recently rewatched The Legend Of Korra and played Ron Gilbert’s Death by Scrolling. The game is beautiful pixelart and such a simple, but engaging premise. It has this “anyone could build this, but building it first not anyone can”. It got me thinking of a 2D roguelike based around elemental powers and how the Avatar premise lends itself so well to some interesting gameplay and progression. Having the premise for a (somewhat) open world would be fun, but also way exceeded the scope I could realistically tackle. So as a tech-demo I started looking at the Pro Bending matches from The Legend of Korra instead.
I have known DragonRuby for at least 5 years. A game toolkit written in Ruby, that comes with a ton of sample games showing core mechanics. Any previous attempt of getting something started always failed, as DragonRuby has an unfamiliar dialect of Ruby and is written almost functional-programming like – think Elixir or Go. I couldn’t fit my thinking into the given data structures. I was lacking a scaffold that matched my brainwires.
Draco enters the room. Build upon DragonRuby, it is a slim Entity-Component-System, that provided exactly the structure I needed. Small in footprint, easy to get started, but easy scalable. An Entity is build from reusable Components, who store data and state. Systems are called with every frame tick and perform actions on entities being composed from the selected components. It lends itself really well for Ruby. So I got started.
I spend the last 6 weeks learning more about Entity-Component-Systems, disassembled Draco and wrote extensions and Pull-Requests. Got my prototype started and refactored it twice. My to-do list grew to 100+ items, half of which are done at this point. I spent hours collecting assets from OpenGameArt and Itch.io. I had to get out my old text books from university and learn about traditional game AI (steering behaviors, path finding & decision making). I broke my brain on seemingly simple mechanics and spent way too much time on unimportant stuff like transitions, menus, and ever more elaborate mock-up art.
So am I done? Not yet. The first build slowly gets to a shareable version soon.
Ich hob meine Hand als auf Arbeit eine alte Leinwand abzugeben war. Ich hatte im August 2025 gerade Acrylfarben gekauft, weil ich meinen Fahrradhelm bemalen wollte, aber nun war die Chance für etwas Größeres.
Ich hatte schon eine Idee. 2026 feiert mein virtuelles Motorsport-Team RaceCar 25 Jahre Jubiläum. Das Jahr gehört mit meinem Co-Gründer Felix zu feiern. Wir hatten schon lange drüber geredet Wandbilder zu drucken, doch nun war hier diese leere Leinwand.
Ich hab seit Schulzeiten nicht gemalt und war damals mit Tusche eher erfolglos. Am Ende meiner Schulzeit bekam ich von meiner Kunstlehrerin die Bilder zurück, die sie jahrelang als Antibeispiele verwendet hat. Zeichnen ist keine Stärke von mir – aber digitale Visualisierungen kann ich. Also ging es los mit zwei Motiven, die ich als Vektoren digital nachgezeichnet habe. Einerseits die Umrandungen, anderseits dann in 15 Ebenen, die verschiedenen Grundfarben der Palette. Ich konnte verschiedene Hintergründe probieren und hatte so eine Vorlage, an der ich bereits wusste, wo ich hinwill und in welcher Reihenfolge alle Elemente gemalt werden müssen.
Gestartet hab ich mit zwei A4-Probebilder an denen ich Pinsel und Farben getestet habe. Ich ich ließ meinen Projektor von der Decke auf meinen Tisch projizieren und musste “nur” noch nachmalen. Sobald die Grundformen stehen, ging es ohne weiter.
Nach den Testbildern ging es an das Große. Auf 110x90cm übermalte ich erst die alten Aufdrücke. Ich liebe an Gemälden die Oberfläche, die Dreidimensionalität der Farbe, die Maserung. Diese erste weiße Schicht brachte Unebenheit, Textur. Druck ist glatt, sauber. Malerei ist uneben, ich mag das Unperfekte, das Zufällige. Ich hatte einige Inspirationen für den Stil, den ich wollte. Ich bin Fan des Impressionismus und mag die Abstraktion des Expressionismus. Der flüchtige Moment, aber im Chaos des Abstrakten.
Nach dem großflächigen Hintergrund kamen Schichten für Details und Schattierungen. Für die silbernen Linien und manche Blau-Schattierungen nutzte ich Metallic-Farben. Das Silber ergänzte ich später sogar mit silbernem Nagellack.
Über den Oktober trug ich so über 14 Abende Farbschicht nach Farbschicht auf. Dies ging sehr reibungslos, während gleichzeitig ein Umzug eine Deadline brachte zu der ich fertig werden wollte. Ende Oktober war es abgeschlossen. Ich ließ es einen Monat liegen und korrigierte danach nur noch einige Kleinigkeiten und unterschriebs.
Ich bin mit dem Ergebnis sehr Happy und überrascht wie leicht man ohne Vorkenntnisse zu tollen Ergebnissen kommen kann. Es gab Learnings bzgl Strichrichtungen, Maserung und Malen an den Rändern, wo rauf ich in Zukunft besser achten kann. Allgemein hat sich für mich der Spruch geprägt: Du brauchst kein Talent, du brauchst du nur gute Vorbereitung.
Fertig eingepackt wartet es nun auf die Übergabe. Felix wusste von nichts und es wurde eine schöne Überraschung beim kürzlichen Besuch.
Und nun? Ich habe weitere Bildideen, die ich jetzt ohne Zeitdruck verfolge. Einige Work-In-Progress werde ich auf Mastodon posten, sobald was zu sehen ist. Mal sehen was als nächstes kommt. Der Fahrradhelm ist indes immer noch nicht bemalt.
Mit dem Beginn der Covid-Pandemie begannen 3 Jahre, in denen ich sehr viele Games spielte und einige bereitsweiterempfohlenhabe. 2023 wurde das letzte große Jahr, in dem ich über 25 Spiele begonnen habe. Ich merkte gegen ende aber auch eine Müdigkeit und 5 Spiele habe ich nicht zu ende gebracht. Danach spielte ich nur noch vereinzelt mit etwas über 5 Spielen pro Jahr. Dennoch lohnt sich mal wieder eine Liste an Spielempfehlungen.
Im Dezember 2019 erschien nach über 9 Monaten Arbeit meine erste EP “Bettlektüre”. Dann kam die Pandemie, ein Umzug nach Wien, 2 Job-Wechsel, neue Hobbies. Ich schrieb weiter Songs, aber wenn ich versucht habe etwas aufzunehmen, klang es nicht. Mein Spielen hatte ein Plateau erreicht. Können und Erwartung gingen nicht zusammen.
Ich weiß leider nicht mehr, wo ich diese Grafik her habe, aber sie half mir zu verstehen, in welchem Cycle ich mich immer wieder fand. Mal wuchs mein Skill-Level schneller als ich meine Ergebnisse einschätzte – manchmal stieg meine Erwartung schneller, als die Qualität meiner Ergebnisse.
Ich war fest im “Art Low” und es dauerte lange dort wieder heraus zu kommen.
2023 nahm ich einige Demos auf, die Potenzial hatten und Anfang dieses Jahres war eine davon ein Kandidat den voll umzusetzen. Zur selben Zeit eröffnete sich die Gelegenheit mit einer langjährigen Freundin was aufzunehmen. Mit Svenny stand ich schon bei Ukeboogie regelmäßig auf der offenen Bühne und nun konnten wir im Februar gemeinsame Studiozeit organisieren. Es war toller und chaotischer Nachmittag. Es war ungeprobt und viel improvisiert. Viele Takes, viele Lacher. Es war ein Probelauf der Lust auf mehr gemacht hat.
Lädybug und ich im Studio
Anfang des Sommers war aus den Aufnahmen eine neue Version entstanden. Es ging durch viele Iterationen, manche länger, “dichter”, manche langsamer. Neue Sektionen entstanden und verschwanden. Das Ergebnis ist heute erschienen und damit mein erster Release seit langem. Ich hoffe, der Nächste dauert nicht wieder so lange.
Ich fahre viel Fahrrad in Wien. Wien – diese Stadt, die überall über den Klee gelobt wird, wenn man aber genauer hinschaut sieht man, in was für Kompromissen gute Dinge erkauft wurden. Gerade bei Radstraßen und der Radwegeführung sieht man das oft. Wie gibt sich als Radstadt, aber die Schritte sind klein um bloß niemandem auf die Füße zu treten. Drei Beispiele aus meinem Alltag möchte ich hier kurz beschreiben.
Grasbergergasse
Die Grasbergergasse ist eine kleine Straße mit einseitigem Radweg zwischen einem Kreisel und Rennweg und ist Teil des Tram-Wendekreises an der Station St Marx. Kommt man von der Station St. Marx wird der Radweg erst über einen Parkplatz geleitet, dann als Teil des Zebrastreifen am Kreisel auf die andere Straßenseite, biegt nach links an der Grasbergergasse entlang. Aus der Richtung kommen ist es okay.
Anders, wenn man vom Rennweg kommt. Radweg ist auf der linken Seite, man fährt auf den Kreisel zu und biegt nach Rechts auf die Radspur des Zebrastreifen vor dem Greisel. Früh muss man anzeigen, dass man hier rechts abbiegen will, wenn man irgend eine Chance haben will, das Autofahrer*Innen aus dem Kreisel kommend am Zebrastreifen halten. Fast wöchentlich hab ich hier Situationen, das Autofahrer denken hier noch durchhuschen zu können und mich zur Vollbremsung zwingen. Bei viel Verkehr ist es auch beliebt einfach auf dem Zebrastreifen stehen zu bleiben und den Radweg gänzlich zu blockieren. Derzeit kommt noch eins drauf – die Tram-Linie 18 wird kurzgeführt und nutzt intensiv den Wendekreis. Eine Tram, die aus Richtung Rennweg in der Gasse fährt, fährt Parallel zum Radverkehr auf der anderen Straßenseite: als Tram sieht die nicht, wenn ich aufzeige, dass ich auf den Zebrastreifen abbiegen werde und als Radfahrer kann ich schwer sehen, wie weit die Tram vom Zebrastreifen entfernt ist. Dies brachte auch schon mehrmals Situationen in denen Tramfahrer den Zebrastreifen ignorieren.
Argentinienstraße
Die Argentinienstraße war bis letztes Jahr ein viel befahrener Radweg vom Hauptbahnhof zum Karlsplatz. Wiens Straßen/Radnetzt ist oft so “designt”, dass viele stark-befahrene Straßen keine Radwege haben, dafür Nebenstraßen verkehrsberuhigt, oder Einbahnstraßen sind, die dann für Radfahrer in beide Richtungen freigegeben werden. Oftmals ist es so, dass der gemütlichere/sichere Weg in die Stadt nicht die Routing App ist, sondern ein bestimmter gut ausgebauter Radweg allen Radverkehr einer Umgebung bündelt. Argentinienstraße war so einer und wurde daher 2024 auch zur vollen Radstraße ausgebaut. Die Umsetzung sie toll aus und fährt sich auch wirklich gut, hat nur einen großen Haken. Es wurden die Nebenstraßen nicht angefasst.
Fahrradstraßen in Österreich sind Straßen, für den Radverkehr, in denen jeder Fahrzeugverkehr verboten ist; “ausgenommen davon ist das Befahren mit den in § 76a Abs. 5 genannten Fahrzeugen sowie das Befahren zum Zweck des Zu- und Abfahrens” – Sprich, nichts ist Verboten, alles darf, wenn es nur sagt “ich muss da lang”.
Die meisten Nebenstraßen der Argentinienstraße sind Einbahnstraßen, die abwechselnd Verkehr in und aus der Argentinienstraße herausleiten. Somit wird Autoverkehr aktiv auf die schöne Fahrradstraße geleitet.
Haeussermannweg
Auch der Haeussermannweg ist eine Fahrradstraße, keine lange, aber eine mit viel WTFs.
Der Hauessermannweg ist eine Verlängerung der Barthgasse, die für Autos eine Einbahnstraße ist und im Hauessermannweg von Radfahrer in beide Richtungen genutzt werden darf. Auch hier den Autoverkehr in die Fahrradstraße leitet. Wirklich kritisch ist dies wenn man vom Radweg Anton-Kuhn-Weg kommend, die Baumgasse kreuzen muss um in den Hauessermannweg zu fahren. Regelmäßig kommen Autos aus dem Hauessermannweg wollen links auf die Baumgasse abbiegen und fahren dann in die Radfahrer, die gerade aus kreuzen.
So eine Verkehrssituation zu erzeugen ist schon What-The-Fuck genug, schärfer wird es, wenn man sich vor Ort die Beschilderung anguckt.
Wie gesagt, ist es wieder eine Fahrradstraße in die Autos mittels Einbahnstraßen hineingeleitet werden, ebeneso die Buslinie 80A … und gefördert vom Klima-Energie-Fonds “als Beitrag zum Umwelt- und Klimaschutz”. Danke für diese 80m.
Ich finde ja es braucht viel mehr Autofahrer-Shaming auf Fahrradstraßen.
Bonus Heustadelgasse
Übrigens sind in Wien das meiste Gassen, aber nicht alle. Als Deutscher hab ich bei “Gasse” ein Bild im Kopf. Jedoch nicht dieses Bild.
In my first article, I looked at Generative AI delivering the Plausible Looking Answer. I did not go into the mechanisms of how Large-Language-Models work. This time I’d like to layout how understanding their technology also helps understanding their short-comings and reduces anthropomorphizingthemover and over. Let’s try and have a look into the machine.
Two phases, two layers
To talk effectively about it, we have to look at two phases of working with the Large-Language-Model.
The first is the training phase in which LLM providers feed as much data as they could get their hands on into the model. The training takes months, a-hell-of-a-lot of (copyrighted) data, energy and cooling water. Once training finished, the model is frozen and made available to use by in or by other services.
Once the model is running, you have the first layer of your AI-service – its foundation, hence “foundational AI model”.
The model itself is frozen and state-less. You send it an request and it will generate an answer. It will not learn on or store your input, your prompt. It will not “remember” what you did a minute ago. To achieve something like short-term-memory, we need to build something on top in the application layer. This layer orchestrates between user inputs, access to additional resources, prompting the LLM. receiving and displaying its response. Much of what happens in an AI-services is not in the actual LLM, but happens in the application layer. We will go deeper here at a different time.
The orchestration also makes the model start generating.
Wakey wakey
The lifecycle of an AI request goes through the same three steps continuous steps: the LLM is state-less program running on a server. The server idles waiting for a request, upon receiving a prompt, the server asks the LLM to generate a response – streaming it piece by piece. Upon finish, the server goes back into idle – the LLM not performing any action. Why is it streamed piece by piece? In an attempt to make waiting times of slower models feel shorter.
If you don’t prompt it, the server sits on stand-by. Without a prompt, the LLM is not neither “thinking” nor “resting”. It will not have a spontaneous idea and “wake up”. The LLM behaves like any other server, waiting to be called. The prompt-response-pattern is at the core of every AI service.
Averaging the human knowledge
The process of creating and training a Large-Language-Model is complex and my explanations will be simplified to get the gist.
Training can be [split into more steps](https://magazine.sebastianraschka.com/p/new-llm-pre-training-and-post-training) (Pre-training, Post-Training, Finetuning, etc) but for us the *Pre-Training* is the most important.
What is this Pre-training? It’s the GPT in ChatGPT (Generative Pretrained Transformer). Today’s LLMs are trained over months on all text, books, websites, movie scripts and movies. These have been broken down into Tokens. Instead of “Daniel” or each letter “D”, “A”, “N”, “I”, “E”, “L”, my name has been tokenized to “Dan” & “iel” and during pre-training the algorithm found, that after the token combination “Dan” and “iel” the tokens “Rad”, “cli” & “ff” are slightly more likely than “Sen” & “ff”. The same, but technically more complex happens when building models for audio or video, which are trained on audio, images and video as well.
Remember when I said in part 1 “No words have meanings to LLMs. To an LLM it’s all just symbols”? These tokens are the symbols. They hold no semantic meaning, they are the pieces for computation and for the statistical analysis.
Nothing the model was trained on is actually stored. It is one giant fuzzy database of parameters encoding the statistical relations between tokens and approximating the original data.
I just said approximation, because during training the original input has been compressed into these parameters with losses. It’s more like a vending machine: you select a product, the machine translates your input into the row and column of your choice, but you don’t know which exact article you will get. When selecting Cola, you may get regular Coke, or Diet Coke, or Cola Zero, or Pepsi. It all fits the original request, but something got lost on the way.
It’s not easy to imagine a multidimensional space of parameters describing an approximation of language and knowledge, so we won’t. We’ll stick with two dimension and look at an example.
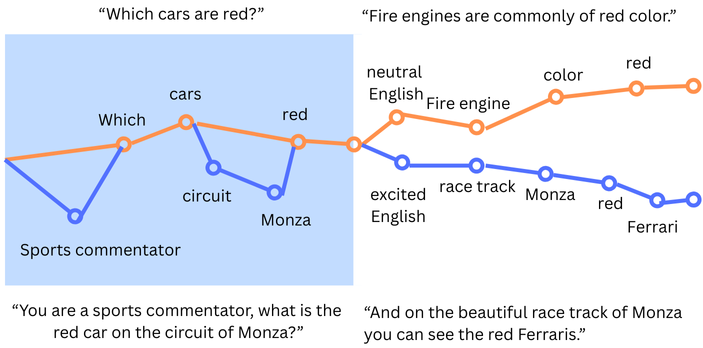
This is fundamental to all LLMs, you pass the initial prompt and it responds with a plausible extension. What’s happening is that your prompt basically draws a path through the model’s billions of parameters and based on this path, it begins generating a response, that itself can go down many different paths.
By changing your prompt, you implicitly describe which parameters get activated in your response. If you ask “Which cars are red?” it may draw a very straight-forward path between the statistics of the word “which” and the word “car”, with a detour through “English language” and may return a response like “Fire engines are commonly of red color.”. Change the prompt to “You are a sports commentator, what is the red car on the circuit of Monza?” the path will also lead though the topics “sports commentating”, “motorsports”, “Monza circuit” and you get a high likely how that “red car” gets related to “Ferrari” in the resulting response “Red cars on the race track of Monza are often Ferraris.”.
Based on this behavior many prompting-strategies have been developed, where providing very specific context can direct the LLM through topics that vastly improve the quality of the response. However no matter the prompting strategy, the LLM will always generate the most plausible path through its data. The generated answer is always an hallucination – just sometimes more correct than other times. It produces text without intent, without interpretation, without malice, without “understanding”. It’s only statistics. The machine is always guesses a text without understanding its meaning, it sees the tokens and attempts to guess an answer from statistics. And sometimes, its guess is right.
Personally, I prefer to avoid the term “hallucination” as it is a euphemism for LLMs producing text which does not stand fact-checking. It’s a machine doing what it is supposed to do, but it is sold by AI providers as more than it can fulfill.
Think harder!
Some LLMs have been extended to work as “Reasoning models”. These add another processing step when generating answers. This is called “thinking”, and can be thought of as an extension to Train-of-Thought. The model will first generate itself a new prompt, that is then being used to fulfill the task. By thus covering a wider context and laying a more detailed path through its data, the hope is to cover more ground and improve the final generated result. This comes at the price of lower response times as the model has to generate even more text, using more tokens and spending more energy.
When addressing these criticisms of wrong responses being hallucinated AI-fans often respond, that this will be fixed in the future and it will get better. The truth so far is is: It will not, as it’s not possible by design with the current technology. Hallucinations are inherit to the design and for the past two years AI providers worked hard to circumvent the most obvious ones on the application layer through moderation. They can’t fix every specific cases on training in the model. Models have mostly grown through data size and scaling, with lower return-of-investment, the bigger they get. Some people already ask, if they have become as good as they can get.
Summary
Whatever you ask your LLM to generate. It will always generate its response from its training data, its corpus. It will recombine, but is it creative? It will not remember, have meaning or understanding. In training any creativity and heart will be averaged out into a statistically plausible response. It will not have creative new “thoughts”. It will walk paths many people before already walked on. It will respond to the next person prompting a similar question with a similar result.
Recombination can bring new ideas and creativity is often a recombination of familiar elements in a new context. To achieve this, you need an understanding of its meaning. Good prompting can lead the model to be a helpful tool, but recognizing creative ideas requires judgement by a human being in front of the keyboard. LLMs produce language, not content. This is where slop is born. I’m reminded of a quote by Kevin Sands, “It is never the tool that decides. It’s the hands-and the heart-of the one who wields it.”.
As such AI can serve as a multiplicator. If you are creative, AI can be one more tool in your toolbox to achieve cool things. If you don’t bring the initial skills, it will make your work look like everyone else’s. If you feed your text into a generative AI to have it reworked, you are literally asking it to remove your personal touch and make it more average and less yours.
Using AI does not make you stand-out, it makes you blend in with everyone else using it.
For a while i’ve been looking for a niche, I have yet to find. If you are a software development company, your product is expensive given the people power and complexity involved. So to have your work financed you have to go in one of two directions:
Either you find one big customer who pays one large amount for your work or you find maaaany customers to pay a small amount.
“One large amount customer” usually means one business customer with a strong dependency coupling, which may be good if the product relationship/product is decent, or bad, if it sucks. Either way you have a co-dependency.
“Many small amount customers” means software needs to scale to millions of users or needs a very special nische. To reach this number, given the initial costs, you need an investor and again you have a strong dependency.
A special role are agencies and software manufacturies, who don’t have an own product and just sell their services.
What I’m missing are examples, of companies who develop their own service or software, maintain a small team size, are bootstrapped and cash positive and have a product, that does neither require millions or users, nor is totally dependent on one sponsor. A product without strong growth pressure. A product that does not need to submit to rot economy.
Generative AI based on Large-Language-Model (LLM) is here, but most people have a vague understanding on what this black box is – how it works, what to expect. This is fine, you don’t have to understand how a solar panel works for getting electricity. However it is important to have an idea of the technology with certain expectation. Generative AI seems like magic when in reality it is all statistics. It looks like human thinking, sensing and feeling, when it is playing pretend. Explaining how LLMs work technically is interesting and also tough, but you can still find some mental images that help to set expectations of what this technology can do and how it operates.
My fallible friend
Your generative AI is like an eager friend. You can ask them any question. They will always have an answer. They will rarely say, “I don’t know” and will bullshit or even gaslight you into thinking, they do have the answer. Oftentimes they are right, but being right yesterday is not indication they will be correct today. Whether they are correct or wrong, or whatever, you only know once you check or question their response. Until it is checked, the response is only plausible.
Sentence completion turned to 11
We all have used the keyboards on our Smartphones. Above the virtual keys, you get a word prediction, where the system tries to anticipate your next word, so you don’t have to type it out. This is partially trained by your typing and reflects common word combinations you may have used. For years, on social media people played with predictive texts. You’d start a sentence and have the word prediction on your phone keyboard complete it. Generative AI and Large-Language-Models just like this, but on steroids. The interaction is always a call & response. You pass a prompt and the LLM will auto-complete your prompt with a plausible looking response.
Plausible looking responses
Much discussion is about LLM responses being correct or false, but these are words, that have no meaning to LLMs. No words have meanings to LLMS. To the LLM it’s just symbols. LLMS have no thinking, no sensing, no concept of reality, of right or wrong, of fiction and non-fiction. LLMs are statistics trained on the internet with all biases, short-comings, copyright-infringements, and grammatical mistakes, there are. The more context you provide, the better its calculation may pass an answer that not only looks plausible, but is actually correct. You can ask an LLM, what the name of the first city on the moon is. If it says “New Berlin”, it gave you the answer from Star Trek. Technically not wrong, not totally correct either.
Similar when you ask for sources. The LLM will always try to create a plausible looking answer. In the answer, you’d expect a list of book titles. Having book titles makes it look more plausible than saying “I don’t know any books of that topic.” Thus it invents book titles, to make a more plausible looking answer.
On a limited scale, you can influence this with your prompt and the AI providers try ensure good looking answers, but this is a fundamental characteristic of the technology. It will generate plausible looking answers.
Hallucinations
When marketing departments companies pushing AI found that too many would generate garbage or fudge details, the term “hallucination” was coined. “Ah, the model is just hallucinating, it’ll improve in the next version”
Hallucination is not the failure of Generative AI, it’s the mechanism by how it works. It’s the statistical recombination that creates a plausible looking answer, given the initial prompt.
It looks like thinking
“But look the train of thought, it’s thinking, it’s reasoning!”
Train of thought is the method of asking the LLM to write down “what are the steps you would do to solve X”. Again, the result will be a plausible looking sequence of steps, but it’s not “thinking” and it’s not the steps the model will actually perform. It’s a generated answer describing the steps. Similarly, when you posed a question to an LLM and ask it “how did you do this”? It will generate a plausible looking answer, describing what a thinking process may have looked liked, but it didn’t think this process, neither has it memory. Apple recently published a paper going into more detail. If you ask a model “how do you feel, what do you want”, it will either respond with a plausible looking answer about being self-conscious and may sound very human doing that, but it’s still only a plausible looking answer. Many AI providers also tweaked their models, to respond to these kind of questions with template answers as too many – even experts – fell into the whole of believing to have found sentient AI. This is Pareidolia.
Doing Chain of Thought when prompting LLMs, it did show improved results by the AI’s response. What it does do is asking the LLM to cast a slightly wider net in it’s training data, thus getting a bit more context from the prompt, extending the level of detail to a degree where the generated response has more context based on fetched trained data and a higher chance of being correct.
How this breaks down can be nicely seen when asking math questions, or counting letters in a word. It doesn’t think, it generates plausible text. “How many letters are in strawberry?” A structurally plausible answer is “There are 5 r in strawberry” – there is no model of a letter, there is no model of a word or of the process of counting. It just knows, that in its billions of training data, statistics show, that a plausible answer looks like this. Applying train of thought, will have the LLM describe how letters are counted, but since it does not actually perform the steps it describes, it may still fail.
The strawberry example has been around long enough, that newer models were trained on articles describing this behavior. They may now return the correct number for strawberry, but now ask for blueberry and they may fail again. Similarly, when you ask to “generate a sentence of exactly 25 words” or “count the elements in this list”.
Summarize all the things
A common generative AI use case often presented are summaries. “Have this e-mail summarized for you!”. Unfortunately it doesn’t summarize. When you ask LLM for a summary, or a transcript, you will have one of two situations.
If the document you want to get summarized is about a topic, that is well documented and included in the pre-trained corpus of your model, when generating the summary it will draw heavily from this trained data and add “outside” knowledge to the document. It may add points not included in the original document, but which may be “plausible” to add. It’s like asking an intern to summarize a document and they will give you the Wikipedia summary.
If the document is on a topic not reflected in the corpus of your model, it can not draw from the training data, so it has to work with what you have given it. In this case, it will analyse the source document and make a statistical guess on what is imported in the document. This would be your intern counting how often the word “opportunity” was mentioned in the document and thus only mention the opportunity, while leaving out the risks because the word “risk” was only mentioned once. Can’t be that important, right?
Your AI friend can help you, or it can fail. Depending on the quality of the model, it can fail hard and invent everything in the quest for the most plausible answer. I know people talking about “human-level AI” to address this. AI is not infallible, it’s only “human-level”. I gave my sister the same explanation, on how LLM don’t do summaries. Her response was “still better than my colleagues”, mine “Get better colleagues”.
Über die Jahre, die ich Berlin meine Heimatstadt nennen konnte, entdeckte ich ein Motiv, dass in der Geschichte der Stadt immer wieder aufkam. Eine stille Sehnsucht, die sich in einem regelmäßig wiederkehrenden Wunsch äußert. Dem Wunsch nach einem richtigen Berg.
2007 lernte ich im Dokumentarfilm “Die Pyramiden vom Treptower Park” erstmals von der einstigen Idee in der Stadt einen künstlichen Berg zu errichten. 1896 fand auf dem Gelände des Treptower Parks die Berliner Gewerbeausstellung statt, die ein deutscher Gegenentwurf zur Weltausstellung in Paris sein sollte, aber ziemlich verregnete. Die Gehwege des Treptower Parks lassen sich bis heute auf die einstiegen Ausstellungen der Gewerbeaustellung zurückführen. Ein Berg entstand nicht, dafür Pyramiden umgeben von viel kolonialem Rassismus.
Ein Jahr später wurde 2008 in Berlin der Flughafen Tempelhof geschlossen und das Tempelhofer Feld als neue Park eröffnet. In den Jahren um die Eröffnung gab es mehrere Ideen-Wettbewerbe über die Gestaltung des Feldes. Neben konventionellen Entwürfen, waren darunter auch eine Segel-Marina und … The Berg.
The Berg war der Vorschlag eines 1200m hohen Berges, aufgeschüttet auf der Fläche des 5km umfassenden Feldes. Eine Seilbahn mit Gondeln in Form von Rosinenbombern würde Skifahrer auf Skipisten bringen. Bergziegen säumen seine Hänge. Am Tempelhofer Bergstübl kann man für Almdudler, Spritzer und Aprés Ski einkehren. Die Illustrationen stehen bis heute online. Der Vorschlag geht mit einer Selbstironie heran un dem Wissen, dass Vorschlag wohl nicht realisiert werden wird, aber in unserem Herzen würde The Berg immer dort sein.
Kaum 10 Jahre später erwachte die Idee eines künstlichen Berges 2019 für zum 40. Geburtstag des Bezirk Marzahn-Hellersdorf zu neuem Leben. Das Künstlerkollektiv Plastique Fantastique errichtete am 7. September 2019 einen kunstvollen und künstlich Vulkan auf den Ahrensfelder Bergen, der für diesen Tag die höchste Erhebung Marzahn wurde.
Doch auch woanders kommt die Idee einen Berg zu errichten immer wieder auf. So auch in den Niederlanden von Thijs Zonneveld, mit dem Vorschlag einen 2km hohen Berg im sonst flachen Land zu errichten. Italien hat indes die Idee bereits vor 1800 Jahren in die Tat umgesetzt. Monte Testaccio ist ein 50m hoher Berg in Rom – aufgehäuft über Jahrhunderte aus antiken Tonscherben. Einst die größte Müllhalde des Antiken Roms beherbergt er heute unterirdische Restaurants.
Doch zurück nach Berlin. Was beim Enthusiasmus über das Errichten neuer Berge oft vergessen wird, ist dass Berlin dies bereits längst gemacht hat.
22 Jahre lang brachten täglich 800 Lastzüge bis zu 7000 m³ Schutt in den Grunewald. Bis 1972 entstand aus 26 Millionen Kubikmeter Schutt der Teufelsberg. Dies benötigte zuvor den gewaltvollen Abriss von 15.000 Gebäuden, einen Regierungsumsturz und eine wohlgesetzte Kugel am 30. April 1945. Ein Drittel des Bauschutt aus der Folge des 2. Weltkrieg endete im Teufelsberg. Weiterer Schutt schufen den Insulaner, den Mont Klamott und weitere Monte Scherbelinos in ganz Deutschland. Der Teufelsberg 120m ist heute mit die zweithöchste Erhöhung des Gebiets von Berlin. Höher als die natürlichen Müggelberge im Südosten, etwas niedriger als die Arkenberge in Pankow im Norden. In 1972 eingeweiht machte er Westberlin ein neues Ski-Gebiet mit Sprungschanze und Schlepplift zugänglich. Der Lift wurde ein Jahr später wieder abgebaut.
Und so schließt sich der Kreis. In Berlin sieht sich in seiner Sehnsucht nach einem Berg, dem Vergessen konfrontiert, was der Stadt bereits Berge gebracht hat. Ich wünsch mir keine neuen Berge. Wer Nazis wählt, ist ein Nazis. Wählt keine Nazis.
Das ist gelogen, das ist 11 Jahre her, aber damals begann ich diesen Text. Nach Abschluss meiner Arbeit wollte ich meine Prozesse dokumentieren, die mir während der Zeit Struktur und Hilfe gegeben haben. Dann kam Leben dazwischen und ich schrieb es nicht zu Ende. Bis heute. Manches mag inzwischen aus der Zeit gefallen sein, aber so kommt das nunmal. Ich habe kürzlich meine ADHS-Diagnose erhalten und seitdem wird mir noch bewusster, wieviel ich in meinem Leben ADHS mit Struktur kompensiert habe. Die Masterarbeit ist hier ein Paradebeispiel. Also, wir spulen zurück.
As I mentioned the other day, I fell in love using Tailscale for making my local private network accessible remotely. I’m also using this in my company, but with one colleague, had an issue, I didn’t find any documented solution online. So here is mine.
I have a Tailscale network with multiple self-hosted services running in Docker and made available with Tailscale. If you have an account and your account is invited to the network, you can access them. This worked for 2 of 3 colleagues. The third had the Tailscale client running on their Windows, it showed up as active in the Tailscale admin console and the list of machines. It looks like it runs perfectly, but when you try access the the service within the network, it fails in Firefox with the error PR_END_OF_FILE_ERROR or SSL_ERROR_INTERNAL_ERROR_ALERT. In other browsers the error would just show as a connection error.
If you put the service in a public Tailscale tunnel, access is possible. if you go on their machine, open Powershell and call tailscale status it would show all status just fine. Calling tailscale ping <service-name> shows success ping to the service.
I tested Windows defender and firewall settings, but could not find anything that could explain the issues.
Calling tailscale dns status provides on the machine provides an overview of the dns options Tailscale is using. Here it showed this:
=== 'Use Tailscale DNS' status ===
Tailscale DNS: disabled.
Tailscale is configured to handle DNS queries on this device.
Run 'tailscale set --accept-dns=false' to revert to your system default DNS resolver.
So I switched this on:
tailscale set --accept-dns=true
Et voila, calling the service work again!
So now I’m in this half-satisfactory space of having a solution, but not knowing the root cause. My guess is that this colleague hasn’t updated Tailscale since them installed it initially in October and when they installed the latest version, it did not install the latest default configurations properly.
My expectation would be that turn Tailscale DNS off again, would lead to the same issue, but it didn’t.
tailscale set --accept-dns=false
So something is weird, is resetted when activated DNS and stays good when deactivating it again. Well it works, for now and I hope it’s a permanent solution.
Es gibt Filme, die holen einen im richtigen Moment ab. Inside Out 1 und 2 waren so Filme für mich.
Inside Out kam während eines “messy breakups”, einer Zeit, die von vielen mentalen Tiefs geprägt war und in der ich mich erstmals mit dem Thema Depression beschäftigte.
In Inside Out 2 erreicht Riley die Pubertät und mit Anxiety übernimmt ein energetisches Chaos das Steuer. Meine Anxieties waren mir lange nicht bewusst. Erst in den letzten Jahren lernte ich diese zu erkennen und einzuhegen.
Nachdem ich aus Inside Out 2 kam, ging ich durch das nächtliche Wien und machte mir Gedanken über die Filme. In Beiden besteht ein eine gewisse Dissonanz wie “groß” das Ereignis in der realen Welt und wie heftig und episch die Reaktionen in Rileys Kopf sind. Wenn ein Umzug, zur gezeigten Verstimmung führt und ein schlechtes Wochenende zur Kapitulation vor Anxiety, ist die Wahrscheinlichkeit hoch, dass diese Episoden keine Einzelfälle sind und Riley öfter mit Mental-Health-Themen zu tun haben wird. Mangelnde Regulation von Emotionen ist ein Symptom von ADHS. Wie cool wäre es, wenn Riley im nächsten Film ihre Diagnose als neurodivers erhält!? Oder im nächsten Film eine neurodiverse Person neben Riley gestellt wird!?
So gingen mir einige Varianten durch den Kopf, wie ich mir von Inside Out 3 vorstellen könnte.
Eine Frau geht durch einen langen Flur. Man sieht ihr Gesicht nicht, aber der blonde Pony lässt keinen Zweifel, dass es sich um Riley handelt. Sie trägt eine Brille – Nahaufnahme ihrer Augen – sie zeigen leichte Krähenfüße und deuten auf ein Alter Anfang 30. Sie stoppt vor einer Tür. Sie fasst den Türgriff, aber hält inne. Sie atmet ein. Das Türschild zeigt “Psychotherapie Dr Erica”. Sie atmet aus und betritt das Zimmer. Ihre erste Therapie-Stunde. Ein Neustart: 20 Jahre depressive Episoden, Selbstzweifel, Rejection-Sensitivity – verkrustete Glaubenssätze warten auf Aufarbeitung und Lockerung.
Zoom in ihren Kopf – an der Konsole streiten sich Ennui, Embarrassment und Fear. Sadness, knackt ihrer Finger: “Lasst uns beginnen!”
Back in 2018 I had a problem. I was writing song lyrics in Evernote, but displaying them for playing was annoying. I started work on Everchords a tiny platform allowing you to connect your Evernote account and display SongPro lyrics beautifully. Over time I added more convenience features for songwriting that helped me a lot to streamline my song writing process. This was a big help when producing Bettlektüre.
All this ended a year ago, when I stopped using Evernote. So it wasn’t part of my workflow anymore. I kept doing security updates, but these took more effort lately. I thought for a long time how to continue it, but ultimately, I don’t know. I’m using Obsidian.md now, which does not have similar APIs. While all data is fully accessible being “just markdown files”, there is no default pipeline to process and there are so many ways to build this pipeline, that it makes little sense to build and maintain a full platform around this. So I decided to take #Everchords offline.
The itch it scratched is still there, as I write my notes in #Obsidian, I may want to have a better songwriting experience again. We will see in time how I will change my process, adopt a different tool set or build something again to cover this.
In part one I spoke about the start of my journey, which was driven by playing with my smart home playground on topics of energy saving. My home servers have been in place since 2018 – yet, one thing I could never fully solve was how to make it available outside of my home network. For people into DevOps there will be little new here, but I’m no DevOps guy, so I had new things to discover I’d like to share.
So my challenge was to make my home server available via the internet, without making it public.
I was toying with a DynDNS setup at one point, but I never felt comfortable with exposing the full device to the internet. I know my way around Linux, but server security can become a bigger beast. I also didn’t want to invest in a virtual private server setup for this.
This is where Tailscale was a small revelation to me. Tailscale is a service provider for virtual private networks. Basically, you install client apps on your devices building a virtual network and making machines available even when they are physically apart. For example, I’m traveling and by flipping a switch on my phone, I see my PCs, my home server, my second phone, and I can access them as if they were in the same room with me. Each device gets a fixed IP and URL in the network and becomes way easier to access than remembering IPs and ports. I could add the Tailscale client to my Home Assistant OS running Raspberry and can access it from everywhere, as long as the Tailscale client is running on my device. This was straight forward.
What took me some time to learn was integrating not only physical devices, but also virtual containers. What is a virtual container? Basically, systems like Docker or Podman simulate a very slim computer environment specifically set-up and optimized to run one particular software stack. For example I can set up a web blog with the client frontend, backend server and database – each running isolated in their own Docker containers – easy to scale. Here you can find more about the basics of Docker and how to get into it step by step. I had my first contact with Docker in 2018, but never got around to fully embrace it until now, but grew to love docker-compose quickly. This allows you to create and find recipes to quickly set up full tool stacks easily and self-host your own software infrastructure.
What is Immich? I wanted to get rid of Google Fotos. I used the service for a long time with much appreciation, but eventually wanted to have more control over my data on the eve of Google using its foto database for AI training, I wanted to withdraw my pictures and also have better organized backups. The easiest alternative I can recommend is ente.io which also comes with more tools around data security and multifactor-authentication (MFA). This option is simple to switch to, but still your data is not in your own infrastructure.
Immich has very similar functionality to Google Fotos and quick to set-up with Docker. You can import your existing fotos either as an external library (very straight forward and simple, but at the cost of small limitations around cleanup options) or by importing all pictures via the API by uploading through the the web interface, the Mobile API, command-line scripts or additional tools like Immich-Go. My photo library has been growing in my filesystem since 2002 and while it is generally well maintained, it slowly became messy, incomplete, metadata was lacking and suffered from duplications. These were all topics Immich and its extended toolchain helped to address. That is, if the photographs are imported in the “right way”. For me it involved three attempts on my side as image duplications on upload, mistaken metadata and lack of testing my own cleanup scripts (xD) caused several broken attempts with Immich. The software is stable and good, but my ambition in cleaning my library was just too big. May the backups be thanked – these setbacks did not cause any data loss – just wasted time. On the third attempt it worked well.up. I picked Immich as one example, but there are plenty more tools available to self-host and especially play nice with Tailscale.
Immich runs on my NUC 11 in a Docker-Compose setup and thus was now available in my home network, but again I wanted it accessible when I’m away from home. This is where we come back to Tailscale. Above we only added physical machines to Tailscale, but it is also possible to add virtual containers to the private network. Each container becomes available as its own machine which now becomes available to everyone in your network to access.
Everyone? Oh, yes, I forgot. You can share your private applications in two ways. You can invite up to 3 people (in the personal free account) to your network and they can have access to all machines if you allow it. Alternative you can share access to single machines to people who already run their own Tailscale network. This way you and your peers are building their own private little part of the internet hosted on your own infrastructure. You can also define machines as exit nodes and thus create your own little distributed VPN. Invite trusted friends over the world and you can run traffic through each other’s exit nodes and now I can watch German Netflix and my friends in Germany can watch Austrian ORF.
Tailscale is providing a good bundle to start your DevOps networking journey. All it offers can be done in other ways with less reliance on a central service orchestrating this network as Tailscale does. However doing this this manually is difficult, complex with a high risk of mistakes that compromises data security – these are factors I’d like to entrust to experts. Tailscale also has a learning curve, but one that is much faster to handle to get into the basics.
Through Tailscale and Docker I have a new toolchain that runs at home, that I have a lot of control over including full ability and responsibility to backup. I picked Immich as one example, but there are plenty more tools available to self-host and especially play nice with Tailscale.
In my next article, I will look into another example, that grew out of Docker and Tailscale at work and that describes a self-hosted alternative approach to a Data Intelligence pipeline in the context of a non-technical company.
I have not been writing code for a year, but my current job is still about providing and choosing technical solutions based on requirements and context. While the company I work for has a strong direction towards GenAI and Microsoft solutions (who doesn’t…), in my private projects I look into the other direction of Small Web, Decentralisation, Self-Hosting and the Rot economy of Tech these days. This also proofed a good opportunity to dive deeper into Home Automation and Docker. It’s an ongoing process, but here I’d like to talk about a few pet projects I did in the last year.
It started back in early summer 2023, I got myself some Shelly smart plugs , installed [Home Assistant]() and began to measure my energy consumption. This ran on my mini-pc – a small Intel NUC 11 Performance – I had been using for a year for backups, but little else. The NUC was an upgrade from a RaspberryPi 3 running dietpi I used for the same purpose. For convenience sake I kept using dietpi also on the NUC 11.
By measuring energy consumption, replacing inefficient devices (ffs get rid of old light bulbs!) I was able to reduce my already low energy consumption by another 20%. Having this visually not only helped reducing total consumption, but also shifting consumption to times windows which are either cheaper by having a lower hourly price or by optimizing for lowest CO2 usage by consuming when most renewable energy is in the grid. Often this coincides with low prices, but not always.
Since working on energy projects professionally and switching to a dynamic energy tariff in February I have been looking more into energy topics. In between I tried to build a predictor that could guesstimate the energy prices for upcoming days based on weather and other factors, but eventually I realized, that this is fruitless as the prices is a negotiated market price based on consumption expectation across all of Europe. To say it simple: the price is not only caused by weather, it’s set to provoke and steer market reaction. I have not the data to predict that.
What is more helpful is experience. On average daily energy is cheapest during the week between 3-4am and 11-2pm. Avoid the 6-8pm evening peak. On the weekend, consume between 11-4pm – sometimes you are lucky and zero to negatives prices. By timing dishwasher and washing machine accordingly, 50% of my consumption falls into the cheapest times. On a regular day, I have 2kWh consumption split with laundry, kettle and dishwasher each at about 1kWh per run being the most hungry devices. Another 1kWh falls to my Tech and I can see in my consumption, when I run the gaming PC with VR. Despite my below-average consumption, I have been dancing around getting a balcony solar-installation for almost a year. At 300€ these have become sooo cheap… story for another day.
I managed all smart home devices in Home Assistant. in the beginning, this ran on the NUC managed by dietpi. Eventually in Spring this year I reactivated the raspberry after all, to run Home Assistant OS on it instead. This offers some more customization and supervising options, necessary to install more custom plugins and integrations. Add the Home Assistant App to this and you have a neat remote for your home. I stopped tinkering here with Home Assistant at this point, although topics like MQTT data broadcasting are still on the list of things I’d like to checkout one day.
Home Assistant at this point was in my local network and only accessible at home. How to make it available remotely and what other infrastructure I started hosting at home, I’ll cover in part two.
Ein Kessel, der ständig überhitzt, unter Druck steht und das erste Mal abkühlt. Die Welt läuft 5% langsamer und erstmals in der selben Geschwindigkeit wie ich. Eine neue Ruhe im Körper – die Anspannung ist weg.
Elvanse lag 8 Monate in meinem Schrank. Zwei Pillen sind einer lieben Freundin vom Laster gefallen für “wenn ich mal schauen will, was an ADHS dran ist”. Seit dem schob ich es immer vor mir her, dieses Experiment zu beginnen.
Dann kam der März. Am Ende meines ersten Experiment-Tages, schilderte ich ihr meine Eindrücke und sie schrieb trocken “Willkommen bei den Neurodiversen”. Elvanse ist ein Amphetamin, eine Stimulanz – mit einem neurotypischen Gehirn, wäre ich an dem Tag aufgedreht durch die Gegend gesprungen. [1] Stattdessen war ich ruhig, entspannt und konnte das erste Mal seit langem drei Stunden konzentriert arbeiten. Alles war zugänglicher, eine komplett neue Körpererfahrung. Damit war es klar. Ich habe ADHS.
Seitdem habe ich meine offizielle Diagnose und ich rede regelmäßig drüber. ADHS endlich bestätigt zu haben ist für mich auch ein Coming-Out. I come in pride. Neu ist mir das Thema nicht, Freunde hatten schon lange die Vermutung und ich wusste ebenso lange, wie ich mich in dem Thema wiederfinde. Gleichzeitig fühlte ich mich wohl Schrödingers ADHSler zu sein und nicht klar als neurodivers oder neurotypisch eingeordnet zu sein. Nun ist diese Einordnung eindeutig.
Die Reaktionen in meinem Umfeld waren fast durchgehend in einem von zwei Lagern: Das “No, shit sherlock”-Camp, dass als Erstes fragte, ob die Diagnose für mich überraschend sei. Dem gegenüber steht das Lager “Rehblick” – Menschen, die mich mit großen Augen überrascht und verständnislos anschauen. Deren erste Frage einfach ist, wie es mir damit geht. Danke sehr gut.
Seit dem Sommer hab ich die offizielle Diagnose und bekomme meine eigenen Medis. Ich bin aufgewachsen als jemand, dem immer eingetrichtert wurde mit Medikamenten solange zu warten, wie es geht. Dies lege ich langsam ab. Für Menschen mit Sehschwäche ist eine Brille ein total normale Hilfe. Für Menschen mit einem anders verdrahtetem Gehirn, sind halt Medikamente die Sehhilfe. Ich hab lang genug gezeigt und bewiesen, wie weit ich ohne komme und zu welchem Preis.
Ein Thema, nach dem ich auch gefragt werde ist, ob ich mit Medikamenten nicht die “Fähigkeiten” verliere, die mich aus machen, bzw die ADHS mir gibt. Ich bin top organisiert, super Problemlöser und klasse in Analyse, Pattern-Matching und letztlich vielseitig und kreativ. Ja, den Gedanke, das zu verlieren hatte ich auch, jedoch hörte aber von allen Seiten, dass dies nicht passieren wird. War auch nicht so. All dies blieb Teil von mir, ich gewinne aber Fokus um es besser umsetzen und stärken zu können.
Trotzdem ist es natürlich nicht nur rosig. Ich freue mich über die Diagnose und die Möglichkeiten nun Erleichterung zu finden. Ich sehe auch, wo ADHS mir in den letzten 30 Jahren viele Steine in den gelegt hat. Manche konnte ich selbst von alleine navigieren – andere nicht. Ich bin stolz, was ich in der Zeit alles hinbekommen habe und es gibt trotzdem auch Momente der Trauer, was mir verwehrt blieb und, dass diese Diagnose Teil meines restlichen Lebens sein wird. Einige Dinge werden niemals leicht werden und ich weiß, wie ich manche Themen derzeit auch noch nach hinten schiebe, wo ich selbst eine neue Position entdecken muss, bzw meine Alte reflektieren werde.
Ich dachte vor 6 Monaten es würde jetzt ein ewig langer Side-Quest beginnen, bis ich Diagnose und die Verschreibung habe. Aber ich bin sehr glücklich, dass durch gute Vernetzung und die Hilfe toller Menschen, alles sehr schnell ging. (Therapeuth*Innen, hört auf die Selbstdiagnose eurer Neurodiversen.) Darüber bin ich sehr dankbar und nun nach einem halben Jahr kann ich mir nicht mehr vorstellen, wieviel Lebensqualität ich ohne die Medikamente auf der Strecke ließ.
[1] Eine andere Freundin schrieb später, sie hätte ADHS herausgefunden als sie gerade feiern war, sich Amphetamine einwarf und wunderte, warum sie plötzlich so hochkonzentriert und fokussiert ist.
Over the past week I have been playing with a self-hosted instance of n8n – a Zapier-like automation platform. I quickly ran into an issue, that took a while to debug and I’d like to share my solution here.
I live in Timezone Europe/Berlin, so I added the timezone ENV-variable. The container starts fine and I can create workflows.
Now the weird thing was that date/time processing was broken.
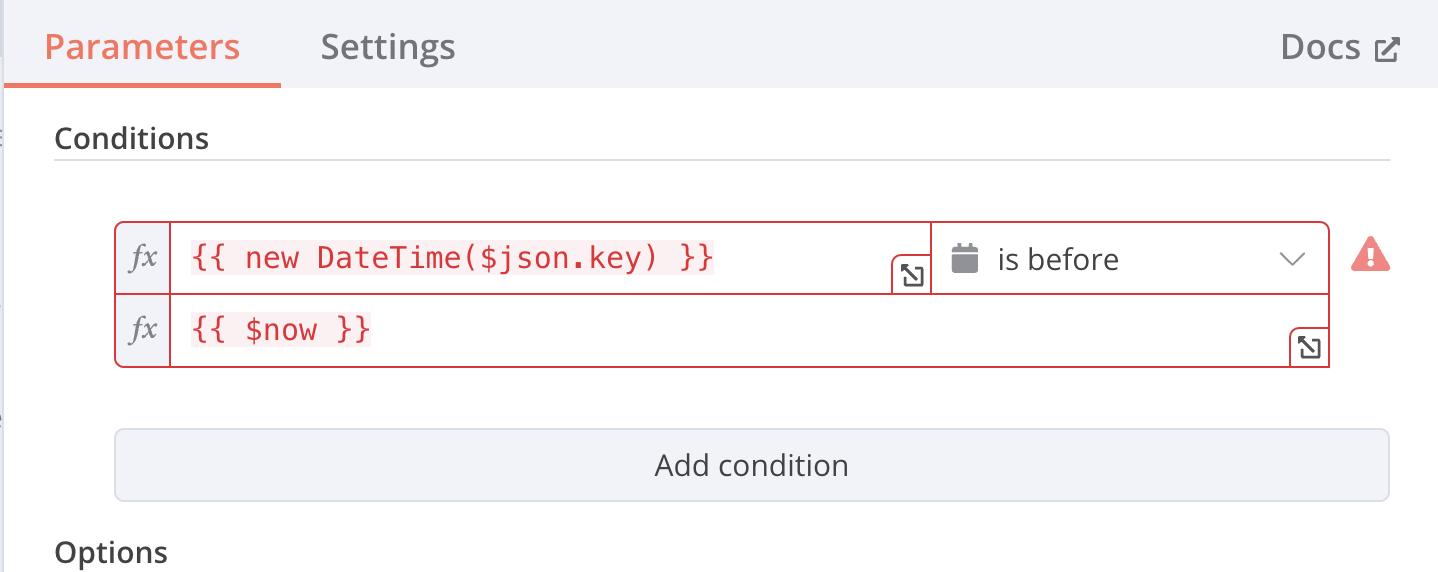
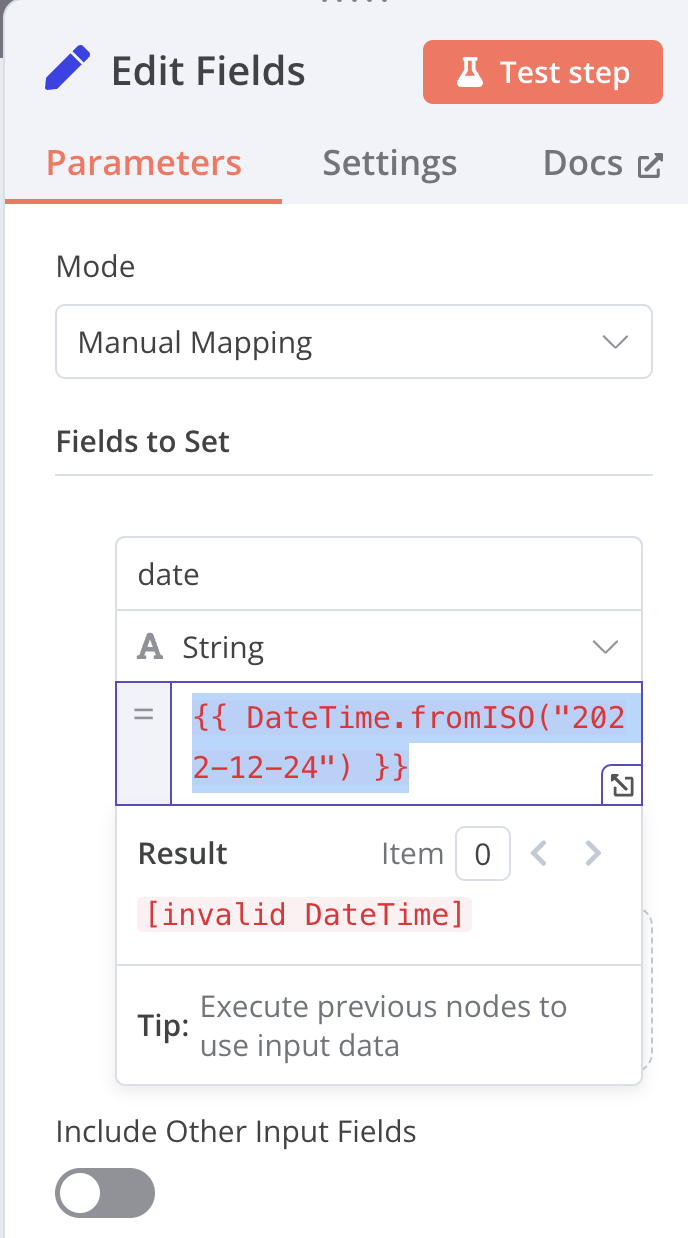
Whenever I would create date/time converting nodes or expressions like {{ $now }} or {{ new Datetime("2024-05-12") }} or {{ DateTime.fromISO("2022-12-24") }} it would always bring up an error message Result: [invalid DateTime]
Which turns out is just wrong… writing it this way has the quotation marks as part of the string thus the timezone n8n was parsing wasn’t ‘Europe/Berlin’. but ‘”Europe/Berlin”‘. Removing this faulty line, the date/time processing with Luxon worked like a charme!
…
- GENERIC_TIMEZONE=Europe/Berlin
–
So getting Invalid DateTime means, luxon fails to parse the timezone and can’t return a valid result. You can try this also with unknown time zones like “Europe/Berlin123” – same error. So fix your time zone config and the error will vanish!