
In my first article, I looked at Generative AI delivering the Plausible Looking Answer. I did not go into the mechanisms of how Large-Language-Models work. This time I’d like to layout how understanding their technology also helps understanding their short-comings and reduces anthropomorphizing them over and over. Let’s try and have a look into the machine.
Two phases, two layers
To talk effectively about it, we have to look at two phases of working with the Large-Language-Model.

The first is the training phase in which LLM providers feed as much data as they could get their hands on into the model. The training takes months, a-hell-of-a-lot of (copyrighted) data, energy and cooling water. Once training finished, the model is frozen and made available to use by in or by other services.

Once the model is running, you have the first layer of your AI-service – its foundation, hence “foundational AI model”.
The model itself is frozen and state-less. You send it an request and it will generate an answer. It will not learn on or store your input, your prompt. It will not “remember” what you did a minute ago. To achieve something like short-term-memory, we need to build something on top in the application layer. This layer orchestrates between user inputs, access to additional resources, prompting the LLM. receiving and displaying its response. Much of what happens in an AI-services is not in the actual LLM, but happens in the application layer. We will go deeper here at a different time.
The orchestration also makes the model start generating.
Wakey wakey
The lifecycle of an AI request goes through the same three steps continuous steps: the LLM is state-less program running on a server. The server idles waiting for a request, upon receiving a prompt, the server asks the LLM to generate a response – streaming it piece by piece. Upon finish, the server goes back into idle – the LLM not performing any action. Why is it streamed piece by piece? In an attempt to make waiting times of slower models feel shorter.

If you don’t prompt it, the server sits on stand-by. Without a prompt, the LLM is not neither “thinking” nor “resting”. It will not have a spontaneous idea and “wake up”. The LLM behaves like any other server, waiting to be called. The prompt-response-pattern is at the core of every AI service.
Averaging the human knowledge
The process of creating and training a Large-Language-Model is complex and my explanations will be simplified to get the gist.
Training can be [split into more steps](https://magazine.sebastianraschka.com/p/new-llm-pre-training-and-post-training) (Pre-training, Post-Training, Finetuning, etc) but for us the *Pre-Training* is the most important.
What is this Pre-training? It’s the GPT in ChatGPT (Generative Pretrained Transformer). Today’s LLMs are trained over months on all text, books, websites, movie scripts and movies. These have been broken down into Tokens. Instead of “Daniel” or each letter “D”, “A”, “N”, “I”, “E”, “L”, my name has been tokenized to “Dan” & “iel” and during pre-training the algorithm found, that after the token combination “Dan” and “iel” the tokens “Rad”, “cli” & “ff” are slightly more likely than “Sen” & “ff”. The same, but technically more complex happens when building models for audio or video, which are trained on audio, images and video as well.
Remember when I said in part 1 “No words have meanings to LLMs. To an LLM it’s all just symbols”? These tokens are the symbols. They hold no semantic meaning, they are the pieces for computation and for the statistical analysis.
Nothing the model was trained on is actually stored. It is one giant fuzzy database of parameters encoding the statistical relations between tokens and approximating the original data.
I just said approximation, because during training the original input has been compressed into these parameters with losses. It’s more like a vending machine: you select a product, the machine translates your input into the row and column of your choice, but you don’t know which exact article you will get. When selecting Cola, you may get regular Coke, or Diet Coke, or Cola Zero, or Pepsi. It all fits the original request, but something got lost on the way.
It’s not easy to imagine a multidimensional space of parameters describing an approximation of language and knowledge, so we won’t. We’ll stick with two dimension and look at an example.
Hallucinations is the mechanism
So you have your fully-trained LLM. When prompting it with a request. you basically ask the LLM “hey, here is this half of a thing, how would the second half look like?”. If you ask it a question, it will create an answer. If you give it an image and ask it to extend the edges, it will create a plausible looking scene, fitting with the original image.
This is fundamental to all LLMs, you pass the initial prompt and it responds with a plausible extension. What’s happening is that your prompt basically draws a path through the model’s billions of parameters and based on this path, it begins generating a response, that itself can go down many different paths.

By changing your prompt, you implicitly describe which parameters get activated in your response. If you ask “Which cars are red?” it may draw a very straight-forward path between the statistics of the word “which” and the word “car”, with a detour through “English language” and may return a response like “Fire engines are commonly of red color.”. Change the prompt to “You are a sports commentator, what is the red car on the circuit of Monza?” the path will also lead though the topics “sports commentating”, “motorsports”, “Monza circuit” and you get a high likely how that “red car” gets related to “Ferrari” in the resulting response “Red cars on the race track of Monza are often Ferraris.”.
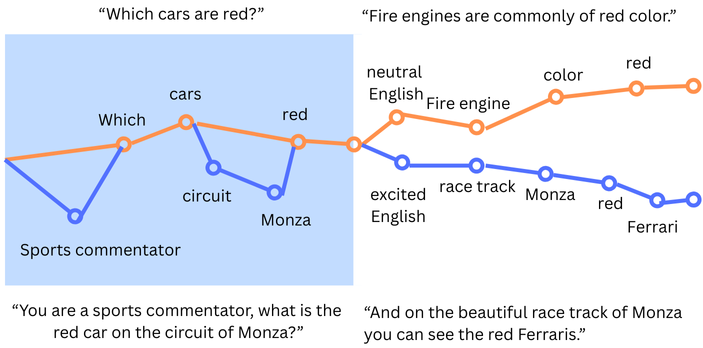
Based on this behavior many prompting-strategies have been developed, where providing very specific context can direct the LLM through topics that vastly improve the quality of the response. However no matter the prompting strategy, the LLM will always generate the most plausible path through its data. The generated answer is always an hallucination – just sometimes more correct than other times. It produces text without intent, without interpretation, without malice, without “understanding”. It’s only statistics. The machine is always guesses a text without understanding its meaning, it sees the tokens and attempts to guess an answer from statistics. And sometimes, its guess is right.
Personally, I prefer to avoid the term “hallucination” as it is a euphemism for LLMs producing text which does not stand fact-checking. It’s a machine doing what it is supposed to do, but it is sold by AI providers as more than it can fulfill.
Think harder!
Some LLMs have been extended to work as “Reasoning models”. These add another processing step when generating answers. This is called “thinking”, and can be thought of as an extension to Train-of-Thought. The model will first generate itself a new prompt, that is then being used to fulfill the task. By thus covering a wider context and laying a more detailed path through its data, the hope is to cover more ground and improve the final generated result. This comes at the price of lower response times as the model has to generate even more text, using more tokens and spending more energy.

When addressing these criticisms of wrong responses being hallucinated AI-fans often respond, that this will be fixed in the future and it will get better. The truth so far is is: It will not, as it’s not possible by design with the current technology. Hallucinations are inherit to the design and for the past two years AI providers worked hard to circumvent the most obvious ones on the application layer through moderation. They can’t fix every specific cases on training in the model. Models have mostly grown through data size and scaling, with lower return-of-investment, the bigger they get. Some people already ask, if they have become as good as they can get.
Summary
Whatever you ask your LLM to generate. It will always generate its response from its training data, its corpus. It will recombine, but is it creative? It will not remember, have meaning or understanding. In training any creativity and heart will be averaged out into a statistically plausible response. It will not have creative new “thoughts”. It will walk paths many people before already walked on. It will respond to the next person prompting a similar question with a similar result.
Recombination can bring new ideas and creativity is often a recombination of familiar elements in a new context. To achieve this, you need an understanding of its meaning. Good prompting can lead the model to be a helpful tool, but recognizing creative ideas requires judgement by a human being in front of the keyboard. LLMs produce language, not content. This is where slop is born. I’m reminded of a quote by Kevin Sands, “It is never the tool that decides. It’s the hands-and the heart-of the one who wields it.”.
As such AI can serve as a multiplicator. If you are creative, AI can be one more tool in your toolbox to achieve cool things. If you don’t bring the initial skills, it will make your work look like everyone else’s. If you feed your text into a generative AI to have it reworked, you are literally asking it to remove your personal touch and make it more average and less yours.
Using AI does not make you stand-out, it makes you blend in with everyone else using it.